доброго времени суток Аналогичный вопрос здесь уже задавался. но что-то не получается "заточить " под себя условие: А1:А10 =ЦЕЛОЕ(СЛЧИС()*99) Надо сосчитать все числа больше 8, которые не делятся на 3 формула массива =СЧЁТЕСЛИ($A$1:$A$10;(ОСТАТ(A1;3)<>0)*(A1>8)) Где ошибка ?
доброго времени суток Аналогичный вопрос здесь уже задавался. но что-то не получается "заточить " под себя условие: А1:А10 =ЦЕЛОЕ(СЛЧИС()*99) Надо сосчитать все числа больше 8, которые не делятся на 3 формула массива =СЧЁТЕСЛИ($A$1:$A$10;(ОСТАТ(A1;3)<>0)*(A1>8)) Где ошибка ?0mega
Сообщение отредактировал 0mega - Воскресенье, 05.12.2010, 22:15
0mega, раз уж Вы решили работать с формулой массива, то в ней должны быть массивы Условие ОСТАТ(A1;3)=0 - естественно работает только для A1, а не для массива A1:A10, так же как и условие (A1>8) Вобщем надо так:
0mega, раз уж Вы решили работать с формулой массива, то в ней должны быть массивы Условие ОСТАТ(A1;3)=0 - естественно работает только для A1, а не для массива A1:A10, так же как и условие (A1>8) Вобщем надо так:
Serge_007, спасибо за ответ. первая формула очень красивая. Но мои "извилины" не в состоянии такое сгенерировать Вторая формула - это как раз то, что я пытался "родить "
Serge_007, спасибо за ответ. первая формула очень красивая. Но мои "извилины" не в состоянии такое сгенерировать Вторая формула - это как раз то, что я пытался "родить "0mega
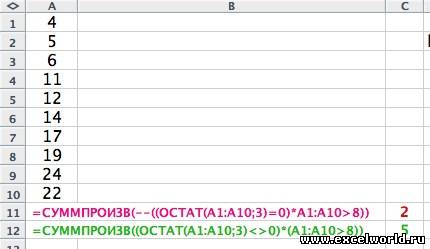
возможно все-таки так: =СУММПРОИЗВ((ОСТАТ(A1:A10;3)<>0)*(A1:A10>8))
нет, это неправильное решение. в условии требуется
Quote (0mega)
... которые не делятся на 3
У Сергея используется =0 т.е. равенство нулю - это подтверждение того, что число делится без остатка. Естественно в первой скобке получается ЛОЖЬ(или НОЛЬ) и дальнейшее умножение на значение >8 дает однозначный ответ 0 В вашем случае получается все зеркально наоборот
возможно все-таки так: =СУММПРОИЗВ((ОСТАТ(A1:A10;3)<>0)*(A1:A10>8))
нет, это неправильное решение. в условии требуется
Quote (0mega)
... которые не делятся на 3
У Сергея используется =0 т.е. равенство нулю - это подтверждение того, что число делится без остатка. Естественно в первой скобке получается ЛОЖЬ(или НОЛЬ) и дальнейшее умножение на значение >8 дает однозначный ответ 0 В вашем случае получается все зеркально наоборот
У Сергея используется =0 т.е. равенство нулю - это подтверждение того, что число делится без остатка.
Именно так Только Вам нужно было обратное Я второпях поменял Ваше условие (ОСТАТ(A1;3)<>0) на своё (ОСТАТ(A1:A10;3)=0, а Вы второпях его не проверили
Вобщем, сори.
Во всех формулах предложенных мной, = надо заменить на <>, тогда они будут работать правильно. Свой пост править не буду, т.к. было обсуждение после. Спасибо DV и kim за бдительность
Quote (0mega)
У Сергея используется =0 т.е. равенство нулю - это подтверждение того, что число делится без остатка.
Именно так Только Вам нужно было обратное Я второпях поменял Ваше условие (ОСТАТ(A1;3)<>0) на своё (ОСТАТ(A1:A10;3)=0, а Вы второпях его не проверили
Вобщем, сори.
Во всех формулах предложенных мной, = надо заменить на <>, тогда они будут работать правильно. Свой пост править не буду, т.к. было обсуждение после. Спасибо DV и kim за бдительность
Нужна помощь. есть БД строк довольно много ~60000. Есть поле "ID" - значения числовые, не уникальные, повторяющиеся сгруппированы вместе, могут быть пустые ячейки, например: "12,12,12,17,17,19,33,33,33,33,33,,,51". Есть поле "name" - текст, повторяющиеся значения, например: "y,y,y,x,x,y,y,y,y,y,y" Любой группе "ID" соответствует одно из значений x,y,z .... нужно подсчитать сколько всего групп ID с name=x Сейчас я считаю так: =СУММПРОИЗВ(1/(СЧЁТЕСЛИ(R[38]C[-1]:R[60171]C[-1];""&R[38]C[-1]:R[60171]C[-1]));--(R[38]C[5]:R[60171]C[5]="x")) это занимает довольно много времени, к тому же подобных выборок будет много - ексель может повиснуть. Можно ли как-то упростить вычисления, пользуясь тем, что все группы ID сгруппированы между собой. Проверить наличие признака X только в первой ячеейке из группы. у меня ексель 2003. Надеюсь понятно описал суть вопроса. [moder]Читайте Правила форума, создавайте свою тему с примером и оформленными тегами формулами![/moder]
Нужна помощь. есть БД строк довольно много ~60000. Есть поле "ID" - значения числовые, не уникальные, повторяющиеся сгруппированы вместе, могут быть пустые ячейки, например: "12,12,12,17,17,19,33,33,33,33,33,,,51". Есть поле "name" - текст, повторяющиеся значения, например: "y,y,y,x,x,y,y,y,y,y,y" Любой группе "ID" соответствует одно из значений x,y,z .... нужно подсчитать сколько всего групп ID с name=x Сейчас я считаю так: =СУММПРОИЗВ(1/(СЧЁТЕСЛИ(R[38]C[-1]:R[60171]C[-1];""&R[38]C[-1]:R[60171]C[-1]));--(R[38]C[5]:R[60171]C[5]="x")) это занимает довольно много времени, к тому же подобных выборок будет много - ексель может повиснуть. Можно ли как-то упростить вычисления, пользуясь тем, что все группы ID сгруппированы между собой. Проверить наличие признака X только в первой ячеейке из группы. у меня ексель 2003. Надеюсь понятно описал суть вопроса. [moder]Читайте Правила форума, создавайте свою тему с примером и оформленными тегами формулами![/moder]HiHiMAX
Сообщение отредактировал Manyasha - Пятница, 10.07.2015, 12:19