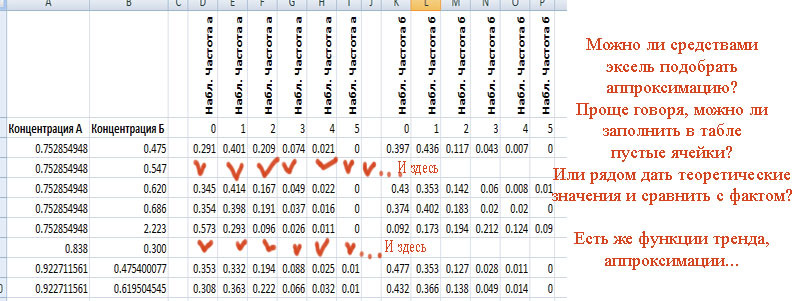
Сорри за многословие, но я и на мат. форумы обращался, и на мехмат МГУ - никто не смог помочь, хотя пятой точкой чувствую, что решение элементарное. Какая-то простая аппроксимация, ИМХО, возможностями эксель вполне можно решить.
Вложенный файл заархивирован прогой 7zip, бо обычный рар сжал хуже. более 100 Кб. Итак. Задача у меня нетривиальная, но интересная.
Имеются 2 вещества А и Б, которые в растворе под воздействием одного и того же реагента, дают реакции А - реакцию а, Б - реакцию б.
А, Б, а, б между собой не реагируют.
По отдельности к-ва получаемых а и б зависят от концентрации А и Б и прекрасно описываются формулой Бернулли (в файле - лист Аппроксимация по Бернулли, параметр 34,935 нашел подбором, кэфы корреляции и совпадения на графике расчетных кривых и наблюдаемых - великолепные). http://ru.wikipedia.org/wiki....B%EB%E8
Взял зависимость конечного продукта а от концентрации исходного вещества А (аналогично - для Б и б), вероятность принял равную Ка/t (концентрация А, деленная на t). Например, концентрация=100, t=10000, Ра=0.01, тогда за время t=10000 вероятность появления количества а от 0 до 100 строго по формуле Бернулли. В предположении, что, например, при а=10 имеем 10 испытаний с исходом 1 и 9990 испытаний с исходом 0.
Выход продуктов а и б округлил до целых, чтобы не заморачиваться.
А при помещении растворов в одну емкость начинаются казусы. Словно влияют друг на друга вещества, хотя считается. что влиять не могут.
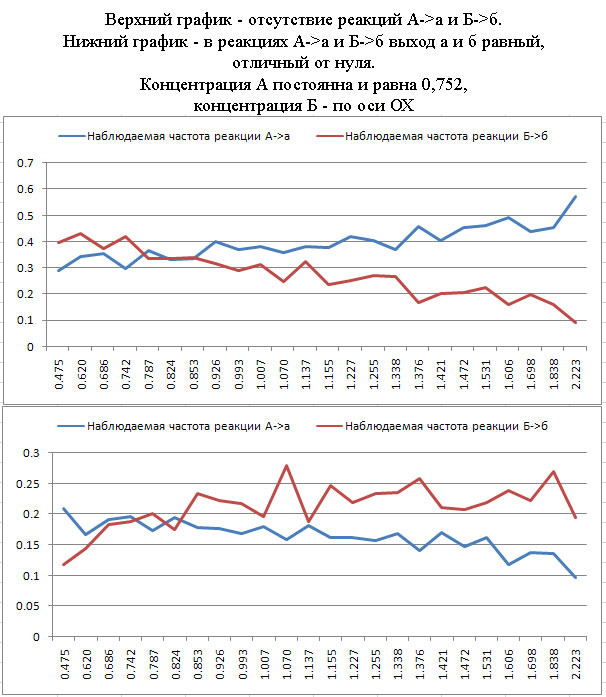
Например, при повышенной концентрации А оно словно тормозит реакцию Б->б, и наоборот... Проведено большое к-во опытов (более 10000), данные сгруппированы следующим образом, уже не в числах, а в долях (шаг 0.05, почему-то ни разу не было так, чтобы к-во реакций А+Б в одной пробе превысило 2*N, но это к задаче не относится): А Б А=0 Б (от 0 до N) А=0,05 Б (от 0 до N) . . . А=N Б (от 0 до N)
С раскладкой по вероятностям получения а (от 0 до n. по Бернулли). Аналогично - для Б в зависимости от А. Как описать это формулами?Как аппроксимировать? Предполагаем, что опытов достаточно, чтобы вывести зависимости. Чтобы, зная концентрацию веществ А и Б, априори определять вероятности реакций А->б и Б->б и количественные значения продуктов а и б. Пока я дошел в формализации до следующего: Сделал многомерную матрицу (условно матрицу, ессно, пока всё в черновиках). Сгруппировал концентрации А и Б в интервалы, нашел значения середин интервалов... По 30 тех и тех. Итого 900 интервалов АБ. Нашел наблюдаемые частоты появления а и б.
На графике - пучки кривых получаются. Понимаю, что это случайный процес, но, как собака Павлова, сказать не могу выразить формулами полученные данные не могу...
На графиках явно видно, что с повышением концентрации Б растет наблюдаемая частота отсутствия реакции А -> а и падение наблюдаемой частоты отсутствия реакции Б -> б и, наоборот, падает наблюдаемая частота А -> а и растет Б -> б. Но по какому закону?
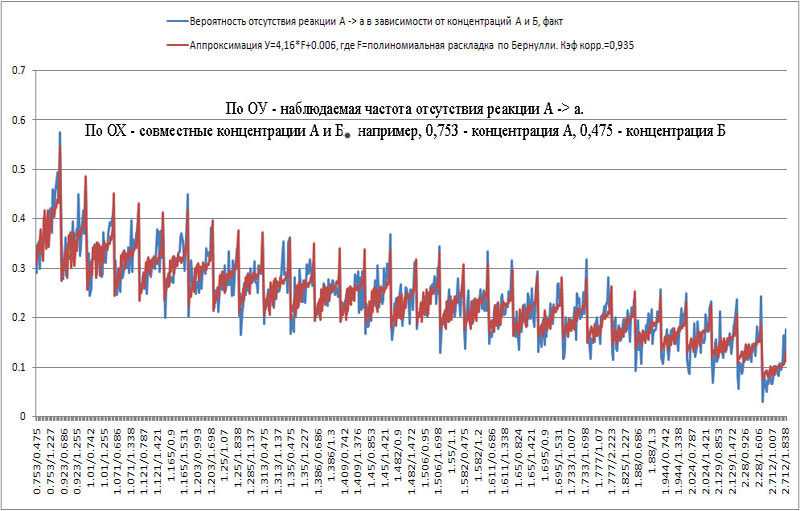
Полиномиальное распределение по Бернулли - увы, через коленку.
Пришлось натяжку допустить. Заметив, что кэф корреляции (между фактически наблюдаемыми значениями и расчетными) очень высок, приподнял теоретическую кривую. В первом приближении и для обсуждения годится, но, согласитесь, не комильфо манипулировать:
Всем - здравствовать.
Сорри за многословие, но я и на мат. форумы обращался, и на мехмат МГУ - никто не смог помочь, хотя пятой точкой чувствую, что решение элементарное. Какая-то простая аппроксимация, ИМХО, возможностями эксель вполне можно решить.
Вложенный файл заархивирован прогой 7zip, бо обычный рар сжал хуже. более 100 Кб. Итак. Задача у меня нетривиальная, но интересная.
Имеются 2 вещества А и Б, которые в растворе под воздействием одного и того же реагента, дают реакции А - реакцию а, Б - реакцию б.
А, Б, а, б между собой не реагируют.
По отдельности к-ва получаемых а и б зависят от концентрации А и Б и прекрасно описываются формулой Бернулли (в файле - лист Аппроксимация по Бернулли, параметр 34,935 нашел подбором, кэфы корреляции и совпадения на графике расчетных кривых и наблюдаемых - великолепные). http://ru.wikipedia.org/wiki....B%EB%E8
Взял зависимость конечного продукта а от концентрации исходного вещества А (аналогично - для Б и б), вероятность принял равную Ка/t (концентрация А, деленная на t). Например, концентрация=100, t=10000, Ра=0.01, тогда за время t=10000 вероятность появления количества а от 0 до 100 строго по формуле Бернулли. В предположении, что, например, при а=10 имеем 10 испытаний с исходом 1 и 9990 испытаний с исходом 0.
Выход продуктов а и б округлил до целых, чтобы не заморачиваться.
А при помещении растворов в одну емкость начинаются казусы. Словно влияют друг на друга вещества, хотя считается. что влиять не могут.
Например, при повышенной концентрации А оно словно тормозит реакцию Б->б, и наоборот... Проведено большое к-во опытов (более 10000), данные сгруппированы следующим образом, уже не в числах, а в долях (шаг 0.05, почему-то ни разу не было так, чтобы к-во реакций А+Б в одной пробе превысило 2*N, но это к задаче не относится): А Б А=0 Б (от 0 до N) А=0,05 Б (от 0 до N) . . . А=N Б (от 0 до N)
С раскладкой по вероятностям получения а (от 0 до n. по Бернулли). Аналогично - для Б в зависимости от А. Как описать это формулами?Как аппроксимировать? Предполагаем, что опытов достаточно, чтобы вывести зависимости. Чтобы, зная концентрацию веществ А и Б, априори определять вероятности реакций А->б и Б->б и количественные значения продуктов а и б. Пока я дошел в формализации до следующего: Сделал многомерную матрицу (условно матрицу, ессно, пока всё в черновиках). Сгруппировал концентрации А и Б в интервалы, нашел значения середин интервалов... По 30 тех и тех. Итого 900 интервалов АБ. Нашел наблюдаемые частоты появления а и б.
На графике - пучки кривых получаются. Понимаю, что это случайный процес, но, как собака Павлова, сказать не могу выразить формулами полученные данные не могу...
На графиках явно видно, что с повышением концентрации Б растет наблюдаемая частота отсутствия реакции А -> а и падение наблюдаемой частоты отсутствия реакции Б -> б и, наоборот, падает наблюдаемая частота А -> а и растет Б -> б. Но по какому закону?
Полиномиальное распределение по Бернулли - увы, через коленку.
Пришлось натяжку допустить. Заметив, что кэф корреляции (между фактически наблюдаемыми значениями и расчетными) очень высок, приподнял теоретическую кривую. В первом приближении и для обсуждения годится, но, согласитесь, не комильфо манипулировать:
А вопрос собственно какой? Нужно найти математическую зависимость? только не понятно какой параметр и от чего?
Как я понял, математически можно задачу свести к следующему: есть квадратная матрица 30 значений изменений А на 30 значений изменения значений Б (судя по количеству экспериментов матрицу можно сделать и побольше), и количество получаемых а и б в зависимости от А и Б Необходимо найти а и б для произвольного значения А и Б которое может не совпадать с шагом сетки в исходной матрице Я правильно понял задачу?
Если да, то задача сводится к нахождению куда попадают искомые значения для А и Б в матрице и вычисляются а и б, вычислить можно линейной интерполяцией, а лучше кубическим сплайном (но для трехмерного графика с осями АБа и АБб это еще та задачка). Линейную интерполяцию можно посчитать и формулами.
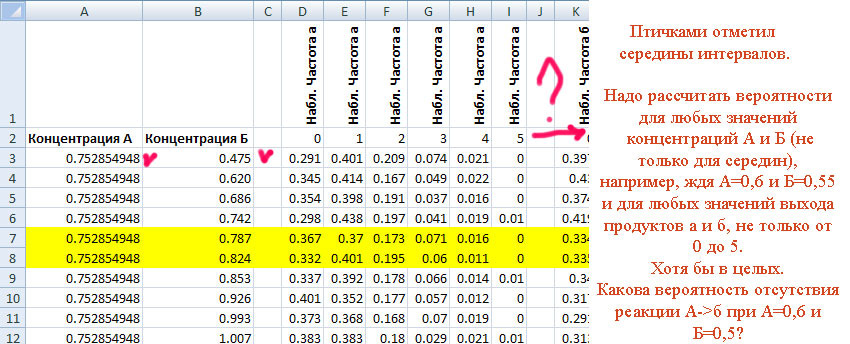
Не понял, что в Ваших таблицах означают числа 1, 2, 3, 4, 5 во второй строке каждой из таблиц? на сколько я понял это само значение а (или б), а в таблице находятся вероятности их появления? Таким образом, нужно найти все 5 вероятностей появления а и б для любой пары А и Б?
А вопрос собственно какой? Нужно найти математическую зависимость? только не понятно какой параметр и от чего?
Как я понял, математически можно задачу свести к следующему: есть квадратная матрица 30 значений изменений А на 30 значений изменения значений Б (судя по количеству экспериментов матрицу можно сделать и побольше), и количество получаемых а и б в зависимости от А и Б Необходимо найти а и б для произвольного значения А и Б которое может не совпадать с шагом сетки в исходной матрице Я правильно понял задачу?
Если да, то задача сводится к нахождению куда попадают искомые значения для А и Б в матрице и вычисляются а и б, вычислить можно линейной интерполяцией, а лучше кубическим сплайном (но для трехмерного графика с осями АБа и АБб это еще та задачка). Линейную интерполяцию можно посчитать и формулами.
Не понял, что в Ваших таблицах означают числа 1, 2, 3, 4, 5 во второй строке каждой из таблиц? на сколько я понял это само значение а (или б), а в таблице находятся вероятности их появления? Таким образом, нужно найти все 5 вероятностей появления а и б для любой пары А и Б?MCH
Как описать это формулами? Как аппроксимировать? Предполагаем, что опытов достаточно, чтобы вывести зависимости. Чтобы, зная концентрацию веществ А и Б, априори определять вероятности реакций А->б и Б->б и количественные значения продуктов а и б.
Параметры - совместные концентрации исходных веществ А и Б (в одном растворе).
Как я понял, математически можно задачу свести к следующему: есть квадратная матрица 30 значений изменений А на 30 значений изменения значений Б (судя по количеству экспериментов матрицу можно сделать и побольше), и количество получаемых а и б в зависимости от А и Б Необходимо найти а и б для произвольного значения А и Б которое может не совпадать с шагом сетки в исходной матрице Я правильно понял задачу?
Правильно поняли. Даже уменьшил в файле размерность матрицы (укрупнил интервалы), бо есть ограничения по к-ву наблюдений (их не должно быть мало, если по-простому).
Если да, то задача сводится к нахождению куда попадают искомые значения для А и Б в матрице и вычисляются а и б, вычислить можно линейной интерполяцией, а лучше кубическим сплайном (но для трехмерного графика с осями АБа и АБб это еще та задачка). Линейную интерполяцию можно посчитать и формулами.
Если бы было так просто. Даже распределение Бернулли косячит, а Вы - линейная интерполяция...
Не понял, что в Ваших таблицах означают числа 1, 2, 3, 4, 5 во второй строке каждой из таблиц? на сколько я понял это само значение а (или б), а в таблице находятся вероятности их появления? Таким образом, нужно найти все 5 вероятностей появления а и б для любой пары А и Б?
Да, это количество а и б (с округлением до целых, укрупнение интервалов, мера вынужденная и обычная в статистике, там и 0 - отсутствие реакции). В мг/л. И ноль - это отсутствие реакции, нет продуктов а и б.
В табле - наблюдаемые частоты (по-простому - да. можно считать это вероятностями, бо к-во наблюдений велико).
Абсолютно точно сформулировали: "Таким образом, нужно найти все 5 вероятностей появления а и б для любой пары А и Б?"
Только не 5 вероятностей, а рассчитать теоретические значения вероятностей по каждому количеству а и б от 0 до 5 (желательно - и далее, но это не стал приводить, если аппроксимация верна. то и для других значений формула будет работать.
Там похоже на полураспад. Есть максимальная (или наиболее часто встречающаяся) величина выхода продукта (а и б) для данной концентрации, и есть распределение, от 0 до... Строго по Бернулли, если отдельно А -> а и Б -> б.
Как описать это формулами? Как аппроксимировать? Предполагаем, что опытов достаточно, чтобы вывести зависимости. Чтобы, зная концентрацию веществ А и Б, априори определять вероятности реакций А->б и Б->б и количественные значения продуктов а и б.
Параметры - совместные концентрации исходных веществ А и Б (в одном растворе).
Как я понял, математически можно задачу свести к следующему: есть квадратная матрица 30 значений изменений А на 30 значений изменения значений Б (судя по количеству экспериментов матрицу можно сделать и побольше), и количество получаемых а и б в зависимости от А и Б Необходимо найти а и б для произвольного значения А и Б которое может не совпадать с шагом сетки в исходной матрице Я правильно понял задачу?
Правильно поняли. Даже уменьшил в файле размерность матрицы (укрупнил интервалы), бо есть ограничения по к-ву наблюдений (их не должно быть мало, если по-простому).
Если да, то задача сводится к нахождению куда попадают искомые значения для А и Б в матрице и вычисляются а и б, вычислить можно линейной интерполяцией, а лучше кубическим сплайном (но для трехмерного графика с осями АБа и АБб это еще та задачка). Линейную интерполяцию можно посчитать и формулами.
Если бы было так просто. Даже распределение Бернулли косячит, а Вы - линейная интерполяция...
Не понял, что в Ваших таблицах означают числа 1, 2, 3, 4, 5 во второй строке каждой из таблиц? на сколько я понял это само значение а (или б), а в таблице находятся вероятности их появления? Таким образом, нужно найти все 5 вероятностей появления а и б для любой пары А и Б?
Да, это количество а и б (с округлением до целых, укрупнение интервалов, мера вынужденная и обычная в статистике, там и 0 - отсутствие реакции). В мг/л. И ноль - это отсутствие реакции, нет продуктов а и б.
В табле - наблюдаемые частоты (по-простому - да. можно считать это вероятностями, бо к-во наблюдений велико).
Абсолютно точно сформулировали: "Таким образом, нужно найти все 5 вероятностей появления а и б для любой пары А и Б?"
Только не 5 вероятностей, а рассчитать теоретические значения вероятностей по каждому количеству а и б от 0 до 5 (желательно - и далее, но это не стал приводить, если аппроксимация верна. то и для других значений формула будет работать.
Там похоже на полураспад. Есть максимальная (или наиболее часто встречающаяся) величина выхода продукта (а и б) для данной концентрации, и есть распределение, от 0 до... Строго по Бернулли, если отдельно А -> а и Б -> б.leon-44
Сообщение отредактировал leon-44 - Среда, 13.11.2013, 00:54
Проанализировал графически данные, Можно изменять значение в S18, и посмотреть графики каждого эксперимента (менять можно с помощью элемента "счетчик") Характеры графиков меняются в разных экспериментах, так Pa(0) чаще всего меньше Pa(1), но в ряде случаев Pa(0) больше Pa(1) и график принимает вид f=1/x, аналогично для Pb(0) и Pb(1) Данный результат может быть связан с не совсем корректной "чистотой" экспериментов, либо с округлением до целых значений (скорее всего второе). Поэтому нахождение аппроксимирующей функции Pa(А;Б;N) и Pb(А;Б;N) методом наименьших квадратов может дать не корректный результат, особенно при экстраполяции данных, выходящих за пределы имеющихся экспериментов.
Проанализировал графически данные, Можно изменять значение в S18, и посмотреть графики каждого эксперимента (менять можно с помощью элемента "счетчик") Характеры графиков меняются в разных экспериментах, так Pa(0) чаще всего меньше Pa(1), но в ряде случаев Pa(0) больше Pa(1) и график принимает вид f=1/x, аналогично для Pb(0) и Pb(1) Данный результат может быть связан с не совсем корректной "чистотой" экспериментов, либо с округлением до целых значений (скорее всего второе). Поэтому нахождение аппроксимирующей функции Pa(А;Б;N) и Pb(А;Б;N) методом наименьших квадратов может дать не корректный результат, особенно при экстраполяции данных, выходящих за пределы имеющихся экспериментов.MCH
Проанализировал графически данные, Можно изменять значение в S18, и посмотреть графики каждого эксперимента (менять можно с помощью элемента "счетчик") Характеры графиков меняются в разных экспериментах, так Pa(0) чаще всего меньше Pa(1), но в ряде случаев Pa(0) больше Pa(1) и график принимает вид f=1/x, аналогично для Pb(0) и Pb(1) Данный результат может быть связан с не совсем корректной "чистотой" экспериментов, либо с округлением до целых значений (скорее всего второе). Поэтому нахождение аппроксимирующей функции Pa(А;Б;N) и Pb(А;Б;N) методом наименьших квадратов может дать не корректный результат, особенно при экстраполяции данных, выходящих за пределы имеющихся экспериментов.
Огромное спасибо за интерес к проблеме!
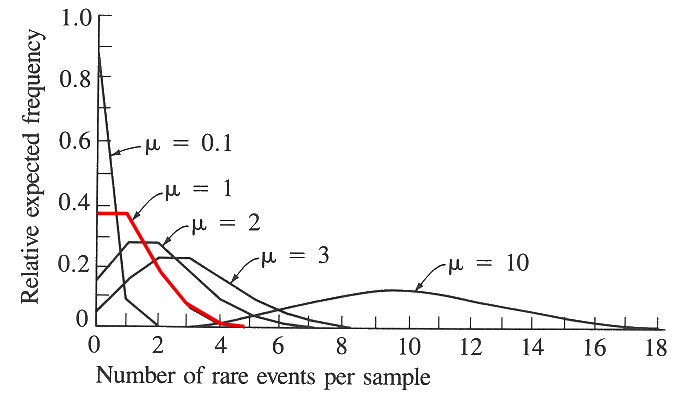
Не волнуйтесь, все нормально, именно так и должно вести биномиальное распределение. Графики надергал в сети, для иллюстрации...
Но всё-таки... Можно ли заполнить пустые ячейки? Исходя из экспериментальных данных, рассчитать теоретические. в том числе и для других значений концентраций А и Б:
Проанализировал графически данные, Можно изменять значение в S18, и посмотреть графики каждого эксперимента (менять можно с помощью элемента "счетчик") Характеры графиков меняются в разных экспериментах, так Pa(0) чаще всего меньше Pa(1), но в ряде случаев Pa(0) больше Pa(1) и график принимает вид f=1/x, аналогично для Pb(0) и Pb(1) Данный результат может быть связан с не совсем корректной "чистотой" экспериментов, либо с округлением до целых значений (скорее всего второе). Поэтому нахождение аппроксимирующей функции Pa(А;Б;N) и Pb(А;Б;N) методом наименьших квадратов может дать не корректный результат, особенно при экстраполяции данных, выходящих за пределы имеющихся экспериментов.
Огромное спасибо за интерес к проблеме!
Не волнуйтесь, все нормально, именно так и должно вести биномиальное распределение. Графики надергал в сети, для иллюстрации...
Но всё-таки... Можно ли заполнить пустые ячейки? Исходя из экспериментальных данных, рассчитать теоретические. в том числе и для других значений концентраций А и Б: leon-44
Сообщение отредактировал leon-44 - Среда, 13.11.2013, 09:55
Возможно задачу нужно свести к нахождению аппроксимирующей функции вида: Pa(N) = K1 * e ^ (-K2*(N - Mu)^2/Sigma^2) ну или другое распределение, (здесь мне сложно подсказать, т.к. теоретической базой в данной области не обладаю) Где K1, K2, Mu, Sigma определяются в зависимости от значений А и Б Сложность как раз будет с определением вида данной функции и нахождением зависимости коэффициентов от А и Б Подбор параметра (поиск решения) думаю подойдет для нахождения коэффициентов при минимизации отклонения расчетной величины от фактической. Трудность может быть с методологией, какую модель выбираем, и как она кореллируется с фактическими значениями
То что вы картиной с галочками показали в предыдущем посте можно решить линейной интерполяцией по соседним точкам, интерполяцией кубическим сплайном (ну или какой сплайн больше нравится), аппроксимацией любым полиномом (линейнным, параболой, третей степени и т.д.), для этого в Excel есть функции ПРЕДСКАЗ() и ТЕНДЕНЦИЯ(), для нахождения коэффициентов полинома аппроксимирующей кривой можно использовать функцию ЛИНЕЙН()
Возможно задачу нужно свести к нахождению аппроксимирующей функции вида: Pa(N) = K1 * e ^ (-K2*(N - Mu)^2/Sigma^2) ну или другое распределение, (здесь мне сложно подсказать, т.к. теоретической базой в данной области не обладаю) Где K1, K2, Mu, Sigma определяются в зависимости от значений А и Б Сложность как раз будет с определением вида данной функции и нахождением зависимости коэффициентов от А и Б Подбор параметра (поиск решения) думаю подойдет для нахождения коэффициентов при минимизации отклонения расчетной величины от фактической. Трудность может быть с методологией, какую модель выбираем, и как она кореллируется с фактическими значениями
То что вы картиной с галочками показали в предыдущем посте можно решить линейной интерполяцией по соседним точкам, интерполяцией кубическим сплайном (ну или какой сплайн больше нравится), аппроксимацией любым полиномом (линейнным, параболой, третей степени и т.д.), для этого в Excel есть функции ПРЕДСКАЗ() и ТЕНДЕНЦИЯ(), для нахождения коэффициентов полинома аппроксимирующей кривой можно использовать функцию ЛИНЕЙН()MCH
Возможно задачу нужно свести к нахождению аппроксимирующей функции вида: Pa(N) = K1 * e ^ (-K2*(N - Mu)^2/Sigma^2) ну или другое распределение, (здесь мне сложно подсказать, т.к. теоретической базой в данной области не обладаю) Где K1, K2, Mu, Sigma определяются в зависимости от значений А и Б Сложность как раз будет с определением вида данной функции и нахождением зависимости коэффициентов от А и Б Подбор параметра (поиск решения) думаю подойдет для нахождения коэффициентов при минимизации отклонения расчетной величины от фактической. Трудность может быть с методологией, какую модель выбираем, и как она кореллируется с фактическими значениями
В файле я и дал наиболее вероятную модель аппроксимации - по Бернулли.
То что вы картиной с галочками показали в предыдущем посте можно решить линейной интерполяцией по соседним точкам, интерполяцией кубическим сплайном (ну или какой сплайн больше нравится), аппроксимацией любым полиномом (линейнным, параболой, третей степени и т.д.), для этого в Excel есть функции ПРЕДСКАЗ() и ТЕНДЕНЦИЯ(), для нахождения коэффициентов полинома аппроксимирующей кривой можно использовать функцию ЛИНЕЙН()
А вот с этого места - поподробнее и помедленнее.
Не просто для чайников - для самоваров. Если не затруднит - файл с примером.. Во вложенном файле округлил концентрации до 2-х знаков и вставил пустые строчки для примеров расчетов аппроксимаций. Непонятно, как совместно аппроксимировать по концентрациям А и Б, если оба параметра меняются.
Возможно задачу нужно свести к нахождению аппроксимирующей функции вида: Pa(N) = K1 * e ^ (-K2*(N - Mu)^2/Sigma^2) ну или другое распределение, (здесь мне сложно подсказать, т.к. теоретической базой в данной области не обладаю) Где K1, K2, Mu, Sigma определяются в зависимости от значений А и Б Сложность как раз будет с определением вида данной функции и нахождением зависимости коэффициентов от А и Б Подбор параметра (поиск решения) думаю подойдет для нахождения коэффициентов при минимизации отклонения расчетной величины от фактической. Трудность может быть с методологией, какую модель выбираем, и как она кореллируется с фактическими значениями
В файле я и дал наиболее вероятную модель аппроксимации - по Бернулли.
То что вы картиной с галочками показали в предыдущем посте можно решить линейной интерполяцией по соседним точкам, интерполяцией кубическим сплайном (ну или какой сплайн больше нравится), аппроксимацией любым полиномом (линейнным, параболой, третей степени и т.д.), для этого в Excel есть функции ПРЕДСКАЗ() и ТЕНДЕНЦИЯ(), для нахождения коэффициентов полинома аппроксимирующей кривой можно использовать функцию ЛИНЕЙН()
А вот с этого места - поподробнее и помедленнее.
Не просто для чайников - для самоваров. Если не затруднит - файл с примером.. Во вложенном файле округлил концентрации до 2-х знаков и вставил пустые строчки для примеров расчетов аппроксимаций. Непонятно, как совместно аппроксимировать по концентрациям А и Б, если оба параметра меняются.